On the future of Sheaf
Feb 2nd 2026
When I started Sheaf in 2025, it came from a frustration with how we express machine learning. I summarized it in the rationale but will extend here.
PyTorch has become the default way to write machine learning code, but over time has also become a dense stack of abstractions, conventions, and implicit machinery. To me, JAX is a clear improvement. It makes the mathematical structure more explicit and pushes important concepts such as pure functions and transformations closer to the surface. Still, at the end of the day, the center of gravity remained the same: Python as the control plane, requiring a growing amount of machinery to compensate for what the language itself does not express.
The issue is not performance per se, but semantic weight. Too much of what matters in a model ends up encoded indirectly, through imperative control flow, decorators, and framework-specific plumbing.
A systems perspective
I come from systems engineering and I tend to think in fairly old-fashioned terms. Unix ideas still resonate with me: explicit structure, minimal runtime assumptions, and components that do one thing and do it well.
Modern ML frameworks tend to violate these principles by necessity. They grow large because they must compensate for the host language. They accumulate features because there is no single place where the structure of computation is represented directly.
At some point, I started wondering what it would look like to approach differentiable programming from the opposite direction: start with a language that represents computation explicitly, and build the numerical machinery underneath it, not around it.
The first mental model was simple: Scheme with tensors and Suckless meets machine learning. Then, more realistically, a Clojure-like DSL on top of JAX.
Sheaf v1
Currently, Sheaf is essentially a functional layer for model description, inspired by Clojure, and delegating numerical execution to XLA via JAX.
This version already does some things well:
- It offers a more mathematical and readable syntax for describing forward passes than most PyTorch code.
- It provides a high density of context for agent-like systems.
- It makes observability a first-class concern, through explicit traces and guards.
- Being implemented in Python, it integrates directly with the ML ecosystem (NumPy, data loaders, visualization tools).
These are real advantages, but they are also narrow. Much of Sheaf v1’s value proposition is framed around Python interoperability: low boilerplate, easy integration, seamless use alongside existing JAX code.
But under closer examination, this is also its main limitation...
If Python is still responsible for initialization, data loading, training loops, checkpointing, and orchestration, then Sheaf is just "yet another layer" to hide the underlying noise instead of removing it. It adds to the problem instead of addressing it at the root.
Envisioning Sheaf v2
The real value of Sheaf lies in what happens when Python is removed from the loop. Sheaf 1.2, releasing this week, is a step forward in this direction. A lot of boilerplate, imperative code has been added, even "functionally impure" forms I was initially reluctant to implement such as a do and while. All examples are now standalone and can do weight loading, checkpointing and training.
But Sheaf remains a DSL on top of Python.
The main goal for the next major release is to break free from Python. To achieve this, the plan is to emit StableHLO and let IREE lower it to Linalg, where Enzyme-MLIR can apply compile-time differentiation. This avoids reinventing autodiff: existing MLIR infrastructure handles it.
Current architecture:

Planned architecture for Sheaf v2:
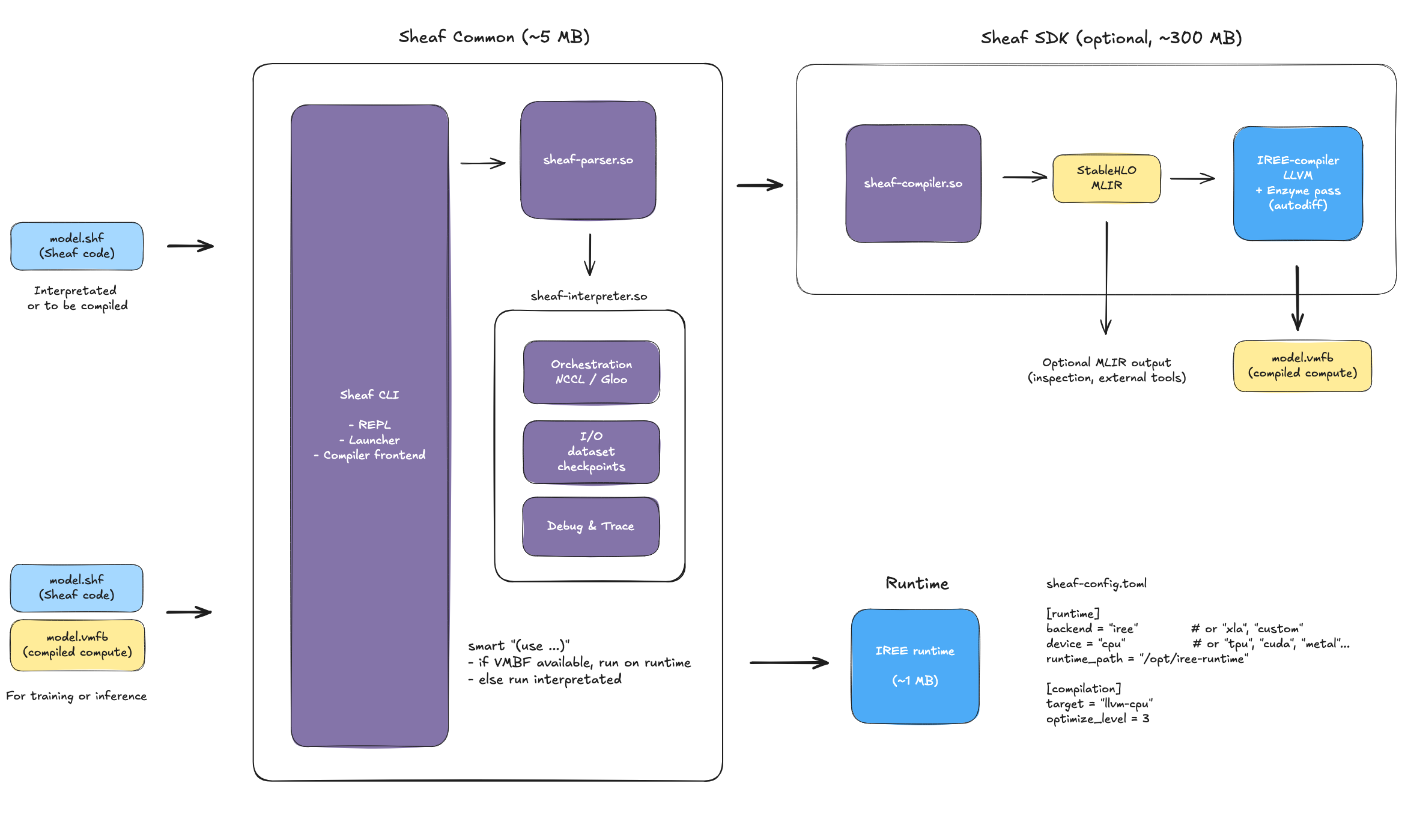
Why IREE and not XLA? XLA is too embedded in JAX's ecosystem. IREE is more modular, and while it depends on LLVM for compilation, LLVM isn't required at runtime for inference or training. I am fine with having LLVM part of the SDK, as long as it's not part of the runtime.
Moving to StableHLO and IREE will not be just an optimization but potentially the game changing aspect of Sheaf v2: on-device training.
With v2, a Sheaf model is shipped as both .shf files and optional .vmfb files. Sheaf files contains orchestration code (dataset paths, checkpointing configuration, I/O, logging) and is the source of truth. The optional .vmfb files contain compiled training computation (forward pass, backward pass, optimizer updates).
The (use ) directive becomes intelligent: if a compiled file exists for the import, it runs it on the IREE runtime. Otherwise, it runs the interprated Sheaf file.
This means zero configuration, zero decorator, and a single command for both development and production.
The runtime contains:
sheaf-parser.so: parser (~2MB)sheaf-interpreter.so: orchestration (NCCL/Gloo for distributed training, I/O for datasets/checkpoints, debug & trace)iree-runtime.a: VMFB execution (~1MB)
Unlike PyTorch Mobile, which only supports inference, the VMFB also supports training. A robot, satellite, or edge device can then train locally without Python, TorchInductor or XLA. The same architecture also scales industrially via SLURM or Terraform (using K8S is asking for overhead). The interpreter handles gradient communication (NCCL all-reduce or Gloo, I will PoC that later) while the scheduler orchestrates worker processes.
Sheaf v2 isn't an entire rewrite but more a completion of vision. The syntax stays, existing Sheaf code works the same, but the Python runtime goes.
What's next
Sheaf 1.2 is coming this week, but I am already thinking heavily about Sheaf v2, notably about how to implement the parser and compiler. Should I write them in C++ or Rust? We want to stay interoperable with Python for data preprocessing: how will we design the Python FFI?
Should Sheaf emit pure StableHLO, or inject higher-level structured ops for better optimization? How will I handle differentiation for the interpreter? How deeply should the compiler integrate with IREE's lowering pipeline?
More on this in the coming weeks.